1st – 2nd July 2021, conference presentation at the International Conference The Future of Education, Virtual Edition
In 1st and 2nd July 2021, the members of the DACRE team attended the 11th edition of the International Conference The Future of Education, Virtual Edition. This is part of the Pixel International Conferences that were previously organised in Florence.
Despite the limits imposed by the current pandemic, the joint efforts of the team members – Roxana Rogobete, Mădălina Chitez, Valentina Mureșan, Bogdan Damian, Adrian Duciuc and Claudiu Gherasim, fom the West University of Timișoara, and Ana-Maria Bucur, from the University of Bucharest – led to the writing of the paper Challenges in compiling expert corpora for academic writing support. You will find out below more information about the paper and the Conference.
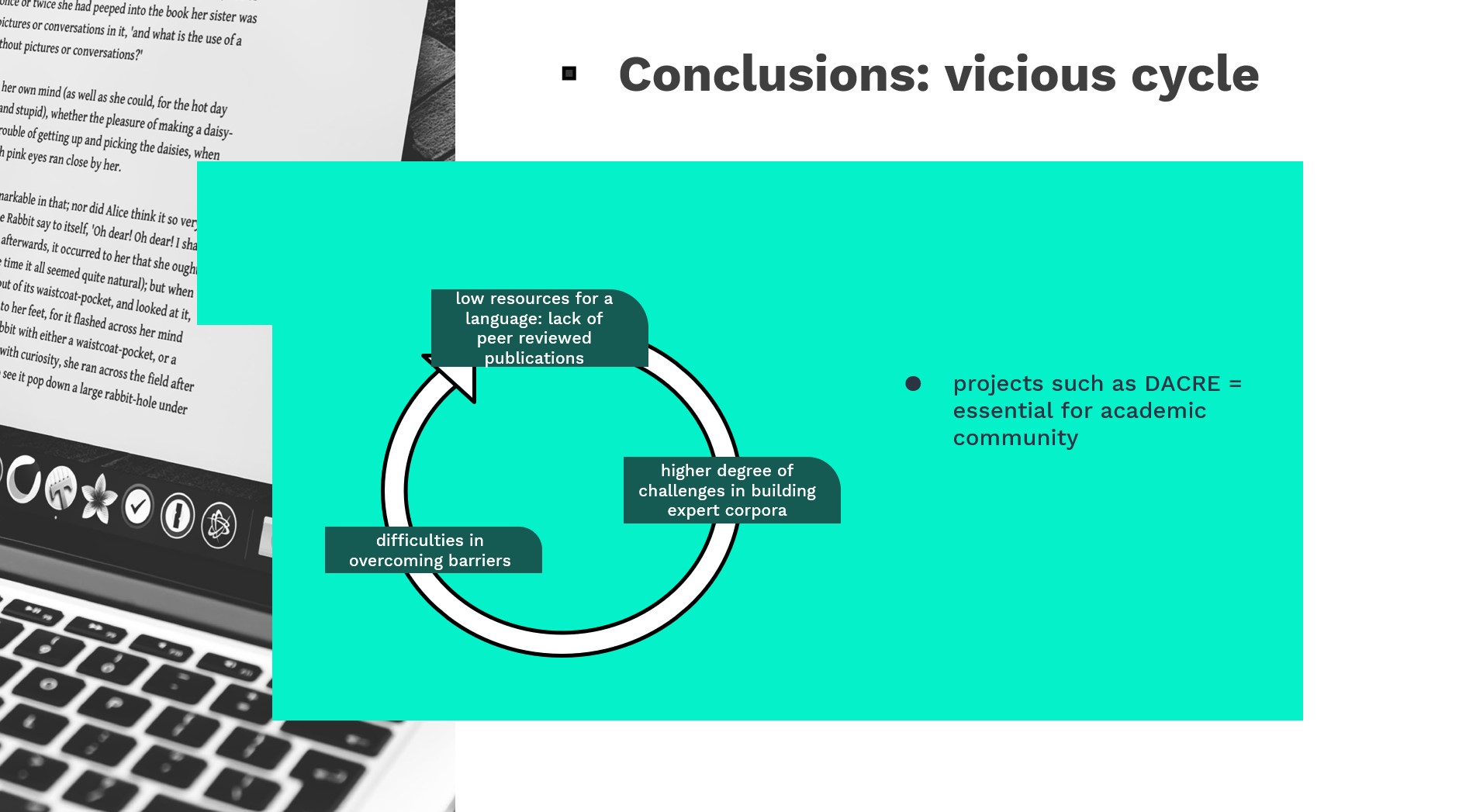
Abstract: The present paper explores a series of challenges faced by Romanian scholars in their attempt to build discipline-specific expert corpora for academic writing. Such corpora are useful when teaching and researching disciplinary writing in L1 Romanian and L2 English. Since many study programs in Romania are also taught in English (IT, Political Science, Economics, for instance), and, moreover, English has been seen for many years as the main academic lingua franca (Mauranen & Randa 2008), most of the academic articles relevant for many disciplines are to be found in English – in addition, papers written in English have a broader impact. The study is based on a bilingual comparable corpus compiled within the DACRE project (Discipline-specific expert academic writing in Romanian and English: corpus-based contrastive analysis models), freshly started in 2021 and financed by the Romanian Executive Unit for Financing Higher Education, Research, Development and Innovation (UEFISCDI) in which we aim to advance the popularisation of corpora in higher education area and create digital instruments and methodological models useful to the national and international language-related research community. The intention of the project is to unfold salient linguistic and rhetorical features specific for each discipline (see Boettger 2016) and each language variety (Romanian, English L1 and L2), as extracted from peer-reviewed scientific articles. At the initial stage of the corpus compilation process, when assessing the linguistic resources to be included in the corpus, a multitude of challenges emerges. For example, the linguistic level of these resources is not consistent (see Yilmaz and Römer 2020). Other difficulties we encountered were the data availability (open sources or subscription-based), lack of recent resources for certain corpus batches, “multi-authorship” in determining L1 texts, and, most important, legal aspects (i.e. copyright). By describing, comparing and analyzing data collection barriers, we propose a model for expert corpus building in English vs in low-resource languages such as Romanian.
To see the Conference Programme, click here.
The final articles can be viewed here.
The team’s paper presentation can be viewed here and the article can be read here.
More information about the conference can be found here.
Poster of the event:

Here are some slides from the PowerPoint presentation of the DACRE team:
Roxana Rogobete, Mădălina Chitez, Valentina Mureșan, Bogdan Damian, Adrian Duciuc, Claudiu Gherasim, Ana-Maria Bucur, Challenges in compiling expert corpora for academic writing support


Conclusions: